




The future of wireless communication requires fundamental change to networks intrinsically fueled by artificial intelligence, and researchers now show how to achieve this ambitious objective. Kobi Cohen-Arazi, Michael Roe and Zhen Hu, as well as their colleagues, have a new framework that transparently integrates algorithms based on python with the processing power of modern graphic processing units. This approach allows automatic learning models to be effectively trained, simulated and deployed in cellular networks, effectively fill the difference between software and hardware. By demonstrating the successful implementation of the estimation of the channels using a convolutionary neural network in a digital twin and a real-time test bench, the work of the team, carried out in the AI Air platform, establishes a crucial base for evolving intelligent 6G networks and unlocks the truly native wireless communication potential.
Modern networks are more and more like artificial intelligence systems, where models and algorithms undergo iterative training, simulation and deployment in adjacent environments. This work offers a robust framework that compiles python -based algorithms in rurable GPU code, resulting in a unified approach that ensures the highest possible flexibility, flexibility and performance on NVIDIA GPUs. As an example of the capacity of the framework, the effectiveness of the execution of the channel estimation function in the PUSCH receiver via a convolutionary neural network (CNN) formed in Python is demonstrated. This process is initially carried out in a digital twin, then validated in a real -time test bench, presenting the practical application and the advantages of the performance of the methodology.
Life cycle without a native and platform development
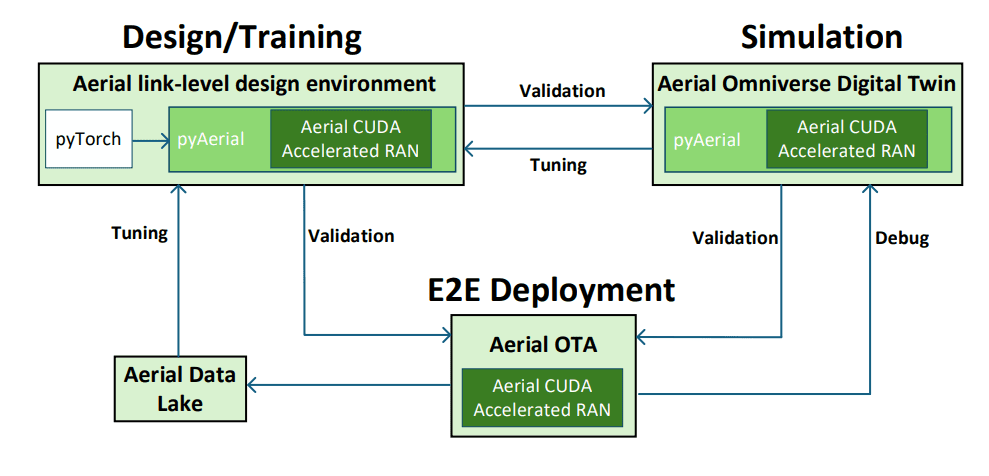
This article details Nvidia’s approach to build a-native wireless communication systems, go from simulation and validation in a digital twin environment to the deployment of the real world. The main idea is to take advantage of the GPUs and a rationalized development life cycle to accelerate the integration of AI / ML models into 5G / 6G networks. The authors offer a new life cycle management process (LCM): design and training, digital twin simulation and real world deployment. This allows in -depth validation before engaging in live network changes. At the heart of this approach is the RAN (ACAR), the NVIDIA platform for the construction of high performance, high performance, high performance, high performance, high-performance GPU, CPU and DPU for optimal performance.
A key component is the use of the Nvidia omaverse platform to create a realistic digital twin of the wireless network, allowing tests and validation of AI / ML models in a simulated environment. The authors have developed a framework to shorten the development time by establishing well -defined interfaces between the modules responsible for the loading and orchestration of the Tensorrt engines, the Nvidia inference optimizer. The experiments demonstrate an improvement of 40% + of the rising bond rate by replacing the traditional estimate of the MMSE channels with a CNN -based approach, both in simulation and in a 5G deployment of the real world. The system uses a Grace Hopper server (GH200) with Bluefield DPUs (BF3) as a hardware platform for GNB and operates the Tensorrt SDK, Nvidia’s inference optimizer for the deployment of AI / ML models. In essence, the article presents a complete approach to the construction and deployment of a-native wireless communication systems, stressing the importance of simulation, validation and a life cycle of rationalized development. The authors demonstrate significant performance gains by taking advantage of the AI / ML models, in particular in the estimation of the channels, and highlight the potential of this approach for future 6G networks.
Python algorithms compiled for nvidia GPUs
This work presents a robust framework to compile python-based algorithms in GPU GPU code, allowing effective and flexible performance on NVIDIA GPUs and laying the base of wireless 6G systems. Scientists have succeeded in a transparent transition from the development of high -level python to a high performance native battery, compiling algorithms in tensorrt engines optimized for NVIDIA GPU equipment. The resulting code contains compiled network information, effectively transforming the Python code into highly optimized Cuda nuclei for direct execution on NVIDIA peripherals. The experiments demonstrate a rapid feedback loop for developers, allowing the refinement of models in Python, compilation in the GPU-utility code and immediate replay on real-time systems, even live.
This iterative process considerably shortens the time of the design of the neural network to deployment. The framework orchestra hybrid calculation graphics, emitting metadata on the entire treatment pipeline and allowing C ++ execution factories to load and place the compiled code correctly in a larger system. This approach exploits the forces of the two CUDA C ++ nuclei personalized for critical digital signal processing stages and the rapid development offered by python -based algorithms. Scientists have succeeded in a unified calculation graph combining the CUDA code manufactured by hand with an optimized Tensorrt code, demonstrating a cohesive system to execute the entire digital signal processing pipeline. This framework facilitates a virtuous cycle where the models are validated, deployed and continuously adjusted, creating a powerful development workflow for new generation wireless communications.
AI and Automatic learning for wireless 6g
This work demonstrates a robust framework to integrate artificial intelligence and automatic learning models in new generation wireless systems, specifically responding to requests from 6G networks. The team has successfully compiled algorithms based on Python in executable code on graphic processing units, making a unified approach that hierartis both efficiency and flexibility. As a practical example, they have implemented a channel estimation function, crucial for receiver performance, using a convolutionary neural network formed in Python and validated by the two digital simulations and a real -time test bench. The realization lies in the establishment of a development cycle, called the “framework for 3 computers”, which transitions in a transparent manner from the initial design and the training, thanks to a rigorous simulation using digital twins, and finally to the deployment of the real world.
This cyclic process allows a continuous validation, adjustment and refinement of the AI / ML models, creating a virtuous circle for optimization. By taking advantage of Python’s accessibility alongside the calculation power of the GPUs, the researchers have laid the foundations for an evolutionary integration of AI into cellular networks. Future research will focus on expanding the capacities of the digital twin for a more complete validation of the model and refining the integration of data in the field in the model adjustment process. This work represents an important step towards the realization of the vision of natively intelligent 6G networks.


