In the field of deep learning (DL), specialized accelerators are essential to meet the increasing computing demands of modern neural networks while ensuring energy efficiency. Systolic array (SA)-based accelerators, composed of a 2D mesh of processing elements (PEs), are widely used to accelerate matrix multiplication, the basic operation of DL models. However, these accelerators often face energy inefficiency issues, especially in cutting-edge AI scenarios with limited energy budgets. Additionally, the sparse and variable computational requirements of modern DL workloads lead to underutilization of PEs because traditional SAs are optimized for dense and regular computations, resulting in idle PEs that consume power without contributing to useful computations.
To address these issues, a research team comprising researchers from institutions such as GIK Institute (Pakistan), Barcelona Supercomputing Center (Spain), Incheon National University (South Korea), Manchester Metropolitan University (UK), Nextwave Inc. (South Korea), and National University of Science and Technology (Pakistan) conducted a study titled “SAPER-AI Accelerator: A Power-Efficient Reconfigurable AI Accelerator Based on a systolic network.
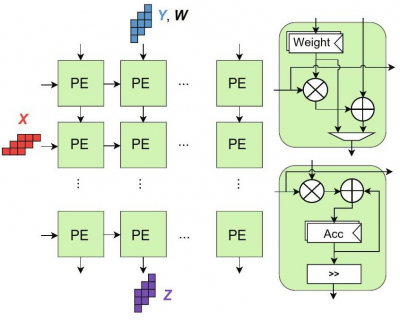
This study presents the SAPER-AI Accelerator, an energy-efficient SA-based reconfigurable AI accelerator that leverages a Unified Power Format (UPF) to specify power intent with minimal microarchitectural optimization effort. The key innovation of SAPER-AI lies in its coarse-grained power management strategy, which deactivates PE rows and columns based on the different computing requirements of different DL workload layers. This allows the SA microarchitecture to dynamically adapt to workload changes, ensuring efficient utilization of active PEs while reducing power consumption of inactive PEs.
The researchers implemented 32 × 32 and 64 × 64 versions of the SAPER-AI accelerator and evaluated their performance using the MobileNet and ResNet50 DL models (trained on the ImageNet dataset) for power, performance, area (PPA) and power delay product (PDP) metrics. The evaluation, carried out using Synopsys tools (Design Compiler for synthesis, VCS for simulation, Primetime for power analysis) with the SAED 32nm technology library, yielded notable results:
- For the 32 × 32 SA design, energy savings of approximately 10% (MobileNet) and 12% (ResNet50) were achieved compared to non-energy-aware designs.
- For the 64 × 64 SA design, the power savings further improved to around 22% (MobileNet) and 25% (ResNet50). Additionally, PDP, an energy efficiency indicator, showed an incremental improvement of approximately 6% for larger SA sizes, with the 64×64 design outperforming the 32×32 version in this measure.
- ResNet50 exhibited better SA performance than MobileNet in both accelerator sizes, attributed to its more regular convolution models that align with the strengths of SA architectures. The performance gap widened as SA size increased, highlighting the impact of workload regularity on SA efficiency.
The article “SAPER-AI Accelerator: An Energy-Efficient Reconfigurable AI Accelerator Based on Systolic Network” is authored by Fahad Bin MUSLIM, Kashif INAYAT, Muhammad Zain SIDDIQI, Safiullah KHAN, Tayyeb MAHMOOD and Ihtesham ul ISLAM. Full text of the article: https://doi.org/10.1631/FITEE.2400867.